Sharded Context Parallelism:极致挖掘 CP 潜力
1. 背景与挑战
1.1 Context Parallelism 的背景
上下文并行(Context Parallelism, CP)已成为扩展长上下文(Long Context)及稀疏注意力(Sparse Attention)模型推理的关键技术。相较于传统的张量并行(TP),CP 具备显著优势(参考 MLSys 2025):
- 低延迟:通过序列维度的并行计算显著降低首字延迟(TTFT)。
- 低通信:节点间通信量远低于 TP,适合跨节点扩展。
- 分布式 KV Cache:KV 缓存容量随设备数线性扩展,有效支撑超长序列。
1.2 现有 CP+TP 架构的瓶颈
然而,当前的 CP 主流实现(如 RFC #22693)通常采用 CP+TP 混合架构。在处理 DeepSeek-V3/V3.2 等稀疏模型时,这种架构暴露出了三大核心局限:
(1) 显存瓶颈:权重冗余存储
在 CP 组内,尽管序列被切分,但每个 Rank 仍需持有完整的权重副本(或 TP 分片)。
- 后果:总显存占用随 CP Rank 数线性增长,严重限制了 CP 在细粒度(如单卡单 Rank)场景下的扩展能力。
(2) 计算瓶颈:稀疏逻辑冗余
每个 CP Rank 内部仍需执行完整的 TP 逻辑。对于 DeepSeek DSA 等稀疏模型,Indexer 模块(负责动态选择活跃 Token)无法通过 TP 并行化。
- 后果:每个 Rank 必须在其本地序列上独立运行完整的 Indexer 逻辑。这导致对大量非活跃/无关 Token 的冗余计算,且冗余量随 CP 规模线性增加。
(3) 存储瓶颈:KV Cache 去重不彻底
虽然 PCP/DCP 实现了 CP 间的 KV Cache 去重,但在 Rank 内部的 TP 设备组之间,KV Cache 仍然是完全复制的。
2. 核心方案:Sharded Context Parallelism
为了突破上述限制,我们提出了 Sharded Context Parallelism(分片上下文并行)。该方案支持单 GPU 粒度的 CP,通过极致的软硬协同设计,实现了显存、计算与通信的三重优化。
2.1 核心创新
- Shard Linear 机制:借鉴 FSDP 思想,按需加载权重,彻底消除权重的冗余显存占用。
- 零冗余计算:每张卡仅计算其负责的序列片段(SeqLen),Indexer 等模块不再重复计算。
- 零通信开销:通过深度流水线优化,完全掩盖 Attention 阶段的通信延迟。
2.2 实验成果
我们在昇腾 910C NPU 的 vllm-ascend 框架中实现了该方案。
- 吞吐提升:在 DeepSeek-v3.2 上获得 336% 的吞吐量提升。
- 长文性能:在 128K 上下文场景下,性能提升高达 500%。
- 开源贡献:vllm-project/vllm-ascend#4702
3. Sharded CP for DeepSeek V3.2
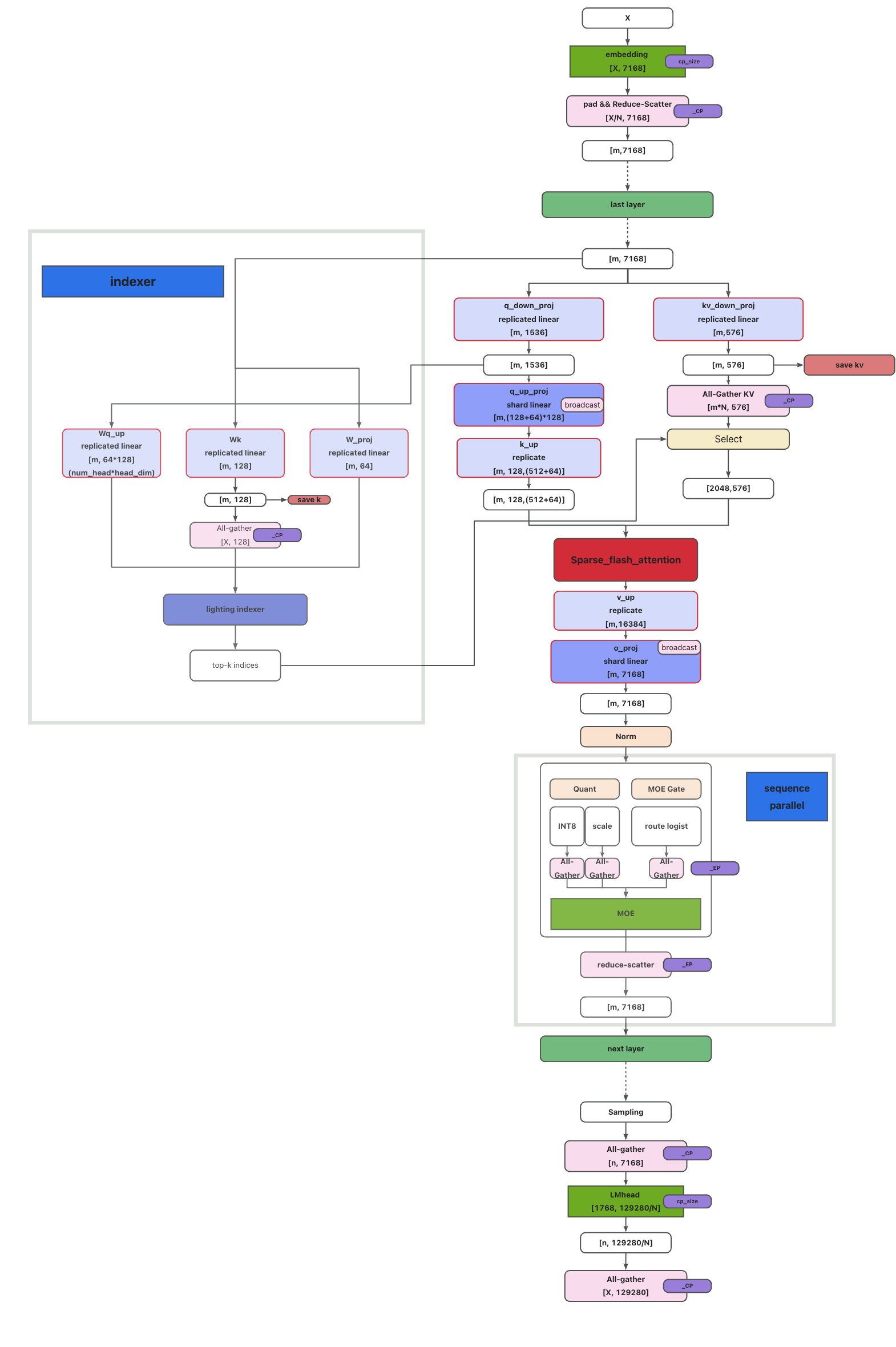
3.1 整体设计架构
DeepSeek V3.2 的 Sharded CP 架构设计如下图所示:
通信消除策略
由于 Attention 权重通常是全量或 TP 冗余存储,我们采取了以下激进策略:
- 消除 Output All-Reduce:利用 CP 特性,每张卡仅输出部分 Token 的结果,直接取消了
o_proj后的 All-Reduce。 - KV Cache 聚合与掩盖:
- 计算 Attention 需要完整的 KV。我们将主模型的 KV Cache、RoPE 以及 Indexer 模块的 K Cache 进行横向拼接。
- 发起一次 All-Gather 操作,将其与计算密集型的
q_up_proj并行执行,实现通信完全被计算掩盖。 - 显存优化:KV Cache 按层通信,用完即存入 Block 或释放,无额外显存峰值。
MoE 部分优化
对 MoE 模块同样应用序列并行(SP)。Attention 结束后,每张卡持有部分 Token 的完整结果。在进入 MoE 之前的 Quant 及 Route Logits 计算后,对结果进行 All-Gather,该过程同样通过计算掩盖实现零开销。
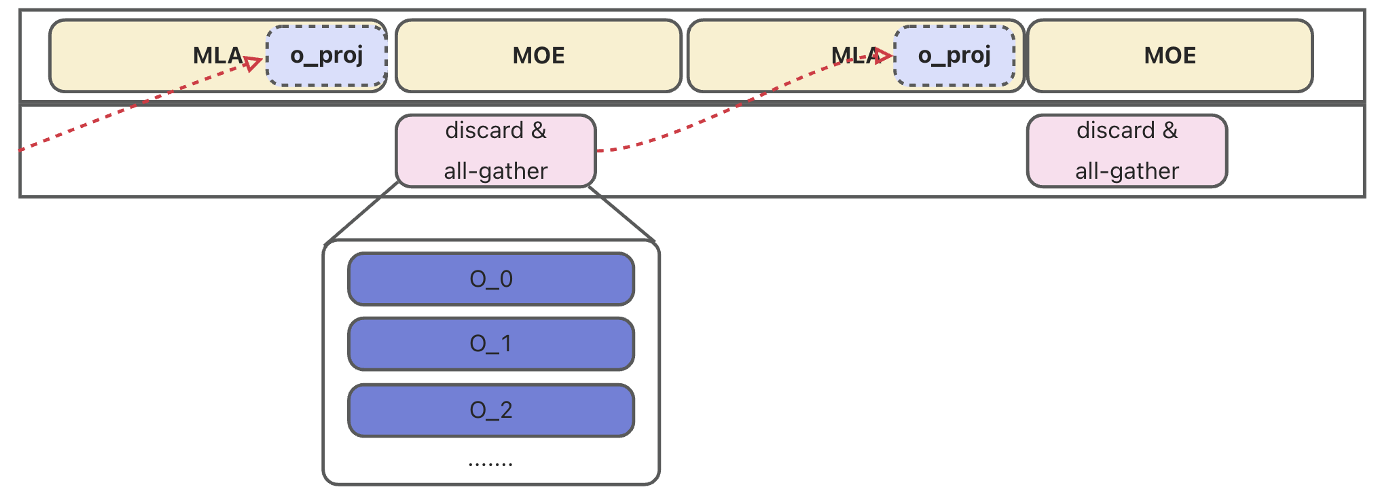
3.2 Shard Linear:权重的极致分片
针对占用 MLA 大部分显存的 Q_proj 和 O_proj,我们引入了 Shard Linear 特性。
设计理念
受 FSDP 启发,Shard Linear 改变了权重的生命周期管理:
- 静态存储:权重以 TP 分片形式静态存储于各卡显存。
- 动态聚合:计算前异步发起 All-Gather 获取完整权重。
- 完整计算:使用完整权重进行矩阵乘法。
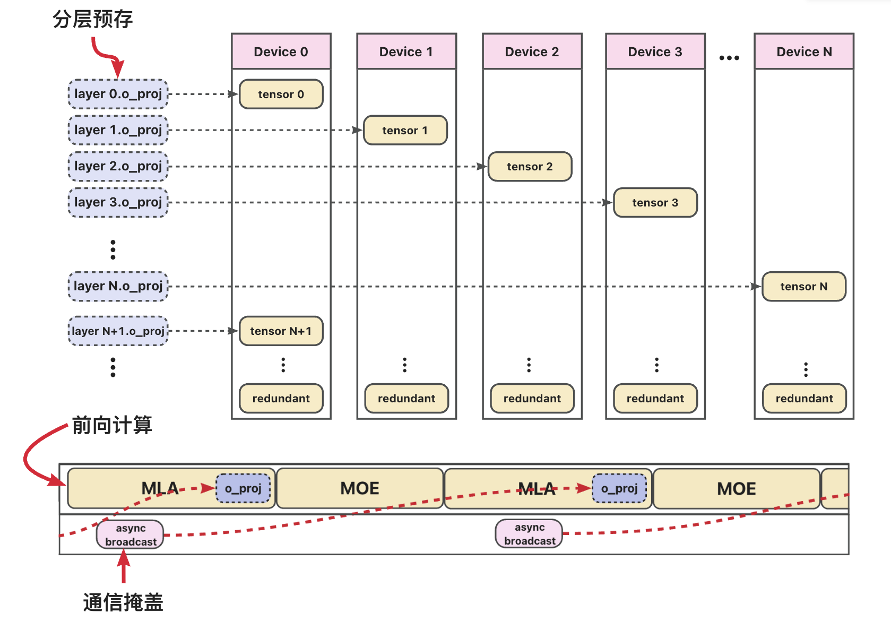
针对 NPU 优化的 Broadcast 机制
由于昇腾 NPU 存在私有权重格式(NZ 格式)及量化属性(Quant Scale 等),直接使用 FSDP 的 All-Gather 会导致格式失效。我们设计了基于 Broadcast 的预取方案:
- 层级分片(Layer Sharding):将各层权重按
Layer ID % Device Count策略分配到不同设备。 - 启动预热:每张卡额外冗余缓存前 $K$ 层的完整权重,确保首 token 推理无延迟启动。
- 异步预取(Asynchronous Prefetch):
- 在 SP 第一阶段 All-Gather 完成后(进入 Attention 前),定位 $L+K$ 层权重所在的源设备。
- 源设备发起 Broadcast,将完整权重分发至所有卡。
- 由于 Prefill 阶段
q_up_proj和FlashAttention耗时较长,Broadcast 通信可被完全掩盖。
- 及时释放:前向计算完成后,立即释放该层权重。
此特性已合入 vllm-ascend 主分支:PR #2931
4. 性能提升分析⭐️
在昇腾平台能拿到如此大的性能提升,我们自己本身也是非常惊讶,也非常兴奋,因为本来我们做prefill的优化能有10%左右的性能提升都算不错的一个关键特性了。对此我针对了性能提升做了非常详细的分析。
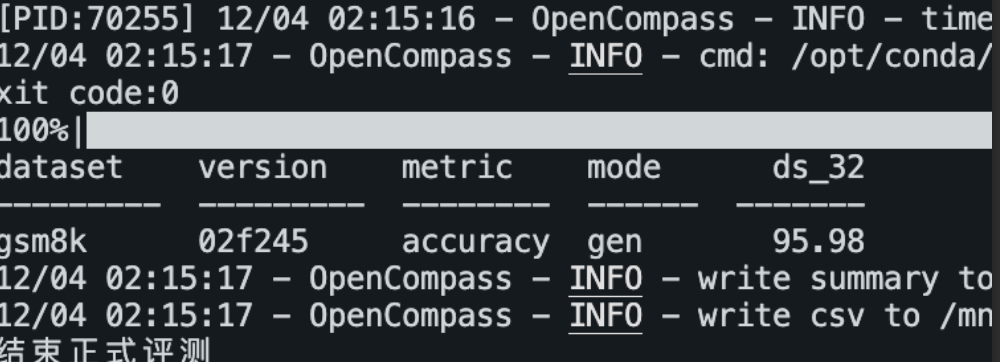
性能提升benchmark图 && gsm8k精度图:

算子性能分析:
首先看性能差异比较大的算子:
1. SparseFlashAttention
profile:

kernel_details:
| 方案 | Device_id | Model ID | Task ID | Stream ID | Name | Type | OP State | Accelerator Core | Start Time(us) | Duration(us) | Wait Time(us) | Block Dim | Mix Block Dim | HF32 Eligible | Input Shapes | Input Data Types | Input Formats | Output Shapes | Output Data Types | Output Formats | Context ID | aicore_time(us) | aic_total_cycles | aic_mac_time(us) | aic_mac_ratio | aic_scalar_time(us) | aic_scalar_ratio | aic_mte1_time(us) | aic_mte1_ratio | aic_mte2_time(us) | aic_mte2_ratio | aic_fixpipe_time(us) | aic_fixpipe_ratio | aic_icache_miss_rate | aiv_time(us) | aiv_total_cycles | aiv_vec_time(us) | aiv_vec_ratio | aiv_scalar_time(us) | aiv_scalar_ratio | aiv_mte2_time(us) | aiv_mte2_ratio | aiv_mte3_time(us) | aiv_mte3_ratio | aiv_icache_miss_rate | cube_utilization(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cp | 0 | 4294967295 | 58111 | 2 | SparseFlashAttention | SparseFlashAttention | dynamic | MIX_AIC | 1764761459549479.309 | 3524.631 | 1.055 | 24 | 48 | NO | “1024,128,512;485,128,1,512;485,128,1,512;1024,1,2048;5,128;5;5;1024,128,64;485,128,1,64” | DT_BF16;DT_BF16;DT_BF16;INT32;INT32;INT32;INT32;DT_BF16;DT_BF16 | ND;ND;ND;ND;ND;ND;ND;ND;ND | “1024,128,512” | DT_BF16 | ND | 0 | 2767.033 | 122856248 | 1270.05 | 0.459 | 1090.331 | 0.394 | 1124.983 | 0.407 | 1901.353 | 0.687 | 1908.977 | 0.69 | 0 | 2769.781 | 245956577 | 802.586 | 0.29 | 2338.385 | 0.844 | 1725.753 | 0.623 | 714.356 | 0.258 | 0 | 75.365 |
| baseline | 0 | 4294967295 | 32713 | 2 | SparseFlashAttention | SparseFlashAttention | dynamic | MIX_AIC | 1764762104173838.715 | 39846.596 | 1.135 | 24 | 48 | NO | “16384,8,512;699,128,1,512;699,128,1,512;16384,1,2048;4,128;4;4;16384,8,64;699,128,1,64” | DT_BF16;DT_BF16;DT_BF16;INT32;INT32;INT32;INT32;DT_BF16;DT_BF16 | ND;ND;ND;ND;ND;ND;ND;ND;ND | “16384,8,512” | DT_BF16 | ND | 0 | 30812.793 | 1368088000 | 5191.721 | 0.168 | 12573.224 | 0.408 | 13614.999 | 0.442 | 24602.17 | 0.798 | 23509.344 | 0.763 | 0 | 30813.542 | 2736242537 | 1104.192 | 0.036 | 28802.779 | 0.935 | 24316.9 | 0.789 | 5973.504 | 0.194 | 0 | 74.235 |
我们来看一下其中的一些关键指标
| 维度 | CP | Baseline | 差异分析 |
|---|---|---|---|
| 执行耗时 (Duration) | 3.52 ms | 39.85 ms | cp 快 11.3 倍 |
| input_shape | [1024, 128, 512]... |
[16384, 8, 512]... |
CP 方案切分 seq,但是保留完整的 head,随维度不同但是数据量相同 |
| output_shape | [1024, 128, 512] |
[16384, 8, 512] |
同上(这里我们可以推断 sfa 的的计算量是完全是相同的) |
| cube_utilization(%) | 75.365% | 74.235% | 利用率相近,说明计算效率相当 |
| aic_mte1_time aic_mte2_time aiv_mte2_time aiv_mte3_time |
1124.98 μs 1901.35 μs 1725.75 μs 714.36 μs |
13614.99 μs 24602.17 μs 24316.9 μs 5973.5 μs |
基本都是 12 倍左右,mte就是 CP 方案快的关键 |
MTE 是 CP 方案中性能提升的 关键
在 华为昇腾AI 处理器(如 Ascend 910)中,MTE 是专门负责数据搬运的硬件单元,与计算单元(如 AI Core 中的 Cube、Vector 单元)解耦并行工作。
由于 CP 方案显著减少了 KV Cache 的读取量,大幅降低了内存传输引擎(MTE)的负担,从而缩短了数据搬运时间。这一优化有效缓解了访存瓶颈,使得 SFA算子中的矩阵乘计算能够更高效地流水执行,最终带来整体性能的显著加速。
为什么 CP 能减少 kv cache 访存 ?
在SFA计算中,baseline 方案采用 TP:每张卡持有完整的 seqlen 的 Q,但只分配部分注意力头,因此需要与对应分片的 KV 进行矩阵乘。
而 CP 方案则不同:每张卡持有部分 seqlen 的 Q,但拥有全部的注意力头,并与完整的 KV Cache 进行计算。
DeepSeek-V3.2 引入了 Indexer 模块,使得每个 token 仅需访问固定长度2048的 KV,而非整个 kv。在此背景下,CP 方案的优势更加凸显:由于每张卡只处理局部序列,它只需加载与该局部 Q 对应的、经 Indexer 筛选后的少量 KV,显著减少了 KV 的读取量。相比之下,baseline 方案中每张卡持有完整的 seqlen,因此需要读取大量的 kvcache,导致在 SFA 执行过程中频繁触发大规模的 MTE操作,造成严重的访存开销和流水线停顿。
因为我们 global 的并行配置 baseline 为 TP16,而 CP 方案为 CP16,理论上 baseline KV 读取量可能是 CP 方案的 16 倍,但是由于每个 token 的 top-k(2048)会有重复,所有 kvcache 读取量 并没有 16 倍的差距。
2. LightningIndexer 的计算
profile:
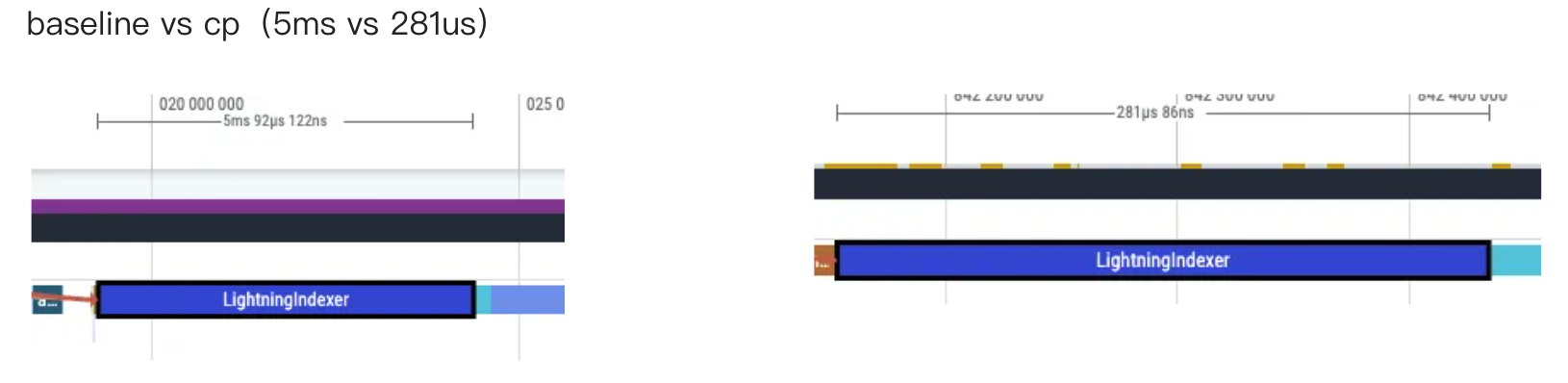
kernel_details:
| 方案 | Device_id | Model ID | Task ID | Stream ID | Name | Type | OP State | Accelerator Core | Start Time(us) | Duration(us) | Wait Time(us) | Block Dim | Mix Block Dim | HF32 Eligible | Input Shapes | Input Data Types | Input Formats | Output Shapes | Output Data Types | Output Formats | Context ID | aicore_time(us) | aic_total_cycles | aic_mac_time(us) | aic_mac_ratio | aic_scalar_time(us) | aic_scalar_ratio | aic_mte1_time(us) | aic_mte1_ratio | aic_mte2_time(us) | aic_mte2_ratio | aic_fixpipe_time(us) | aic_fixpipe_ratio | aic_icache_miss_rate | aiv_time(us) | aiv_total_cycles | aiv_vec_time(us) | aiv_vec_ratio | aiv_scalar_time(us) | aiv_scalar_ratio | aiv_mte2_time(us) | aiv_mte2_ratio | aiv_mte3_time(us) | aiv_mte3_ratio | aiv_icache_miss_rate | cube_utilization(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cp | 0 | 4294967295 | 58109 | 2 | LightningIndexer | LightningIndexer | dynamic | MIX_AIC | 1764761459548934.118 | 282.446 | 0.789 | 24 | 48 | NO | “1024,64,128;485,128,1,128;1024,64;5;5;5,128” | DT_BF16;DT_BF16;DT_BF16;INT32;INT32;INT32 | ND;ND;ND;ND;ND;ND | “1024,1,2048” | INT32 | ND | 0 | 261.516 | 11611319 | 84.575 | 0.323 | 99.695 | 0.381 | 70.886 | 0.271 | 29.714 | 0.114 | 139.095 | 0.532 | 0.005 | 278.619 | 24741398 | 213.992 | 0.768 | 74.65 | 0.268 | 96.997 | 0.348 | 6.258 | 0.022 | 0.005 | 88.886 |
| baseline | 0 | 4294967295 | 32711 | 2 | LightningIndexer | LightningIndexer | dynamic | MIX_AIC | 1764762104168502.129 | 5092.241 | 2.098 | 24 | 48 | NO | “16384,64,128;699,128,1,128;16384,64;4;4;4,128” | DT_BF16;DT_BF16;DT_BF16;INT32;INT32;INT32 | ND;ND;ND;ND;ND;ND | “16384,1,2048” | INT32 | ND | 0 | 4554.882 | 202236777 | 1736.127 | 0.381 | 1781.882 | 0.391 | 1451.462 | 0.319 | 549.574 | 0.121 | 2590.513 | 0.569 | 0 | 5085.976 | 451634633 | 4250.194 | 0.836 | 1419.064 | 0.279 | 1844.032 | 0.363 | 65.617 | 0.013 | 0 | 85.87 |
**关键指标: **
| 维度 | CP | baseline | 差异分析 |
|---|---|---|---|
| 执行耗时 (Duration) | 282.4us | 5092.2us | cp 比 baseline 快 18 倍 |
| input_shape | [1024,64,128]… | [16384,64,128]…. | **关键:**维度差异 16 倍 |
| output_shape | [1024, 1, 2048] | [16384, 1, 2048] | 同上(这里我们可以推断 indexer 在 CP 方案的计算量上远小于 baseline) |
| aic_mte | …. | …. | cp 远小于 baseline(20x) |
| aiv_mte | …. | …. | cp 远小于 baseline(18x) |
lightning Indexer 模块的核心收益来自于消除了 冗余计算
为什么 baseline 中 Indexer 模块的三个矩阵无法在 TP 维度却分?
因为朴素的 TP(Megatron 提出)需要两次矩阵乘来配合,也就是一次行切一次列切,但是 lightning indexer 模块中只有一次矩阵乘就需要,完全的激活去做 top-k,所以在不引入额外通信的前提下就是无法对LightningIndexer 模块的矩阵去做 TP 切分的。
3.其他优化
消除全流程的冗余计算
通信上优化
….
5. 总结与展望
Sharded Context Parallelism 是一次将 CP 理念推向极致的尝试:
- ✅ 打破粒度限制:实现单卡级 CP,最大化硬件利用率。
- ✅ 打破显存限制:Shard Linear 消除权重冗余。
- ✅ 打破计算限制:彻底消除稀疏模型的 Indexer 冗余。
- ✅ 打破通信限制:通过全流程掩盖,实现 Attention 阶段“零”通信。
实测效果:DeepSeek-v3.2 吞吐量提升 336%,验证了该架构在处理复杂稀疏大模型时的卓越效能。
未来计划:
- 将 Sharded CP 推广至更多 Transformer 架构模型,坐等Deepseek-V4😊。