Deepseek细粒度并行优化
在大规模语言模型推理中,Decode 阶段的性能优化面临独特挑战:单 token 生成的 memory-bound 特性使得传统纯数据并行策略在显存占用和访存效率上存在瓶颈。 本文针对 DeepSeek-R1 模型,提出了细粒度张量并行优化方案。通过对 O_proj、LM Head、Embedding 和 Dense FFN 四个关键模块实施跨 DP 组的定制化切分策略,在昇腾平台上实现了 9.72 GB 显存节省 和约 2 ms TPOT 优化,显著提升了 Decode 节点的并发能力。所有优化已开源并合入 vllm-ascend 社区。
1. 背景
1.1 PD 分离架构概述
随着 Prefill-Decoding(PD)分离架构的兴起,vLLM 及其昇腾后端 vllm-ascend 正在积极推进对该架构的深度适配。PD 分离架构通过解耦 Prefill 阶段与 Decode 阶段,并针对各自的计算与通信特性进行独立优化,可以充分挖掘端到端推理性能潜力。
1.2 分布式并行策略差异
在分布式推理系统中,并行策略是实现高效 PD 分离的核心要素。以 DeepSeek 等大规模 MoE(Mixture of Experts)模型为例,通常采用**数据并行(DP)+ 张量并行(TP)+ 专家并行(EP)**的混合并行方案。然而,Prefill 与 Decode 两个阶段在计算模式、内存访问模式和通信开销方面存在显著差异,因此需要采用截然不同的并行策略设计:
Prefill 阶段特征
- 长序列处理:输入序列长度较大(long seqlen)
- 计算密集型:属于 compute-bound 任务
- 最优策略:增大 TP 规模具有双重优势
- 降低单卡显存占用
- 将大规模计算任务分散到多张计算卡,充分发挥并行计算能力
Decode 阶段特征
- 固定序列长度:每次处理的序列长度为 1
- 小批量处理:每次调度的 batch size 通常较小(数十量级)
- 访存密集型:呈现明显的 memory-bound 特征,主要瓶颈包括:
- 计算量相对较小
- 需要支持高并发推理
- 现有策略问题:Decode 节点通常采用**全 DP(纯数据并行)**策略
- 要求每张计算卡存储完整的模型权重(非 MoE 场景)
- 矩阵乘法运算时需读取更大的权重数据量
- 相比 Prefill 阶段,访存开销显著增加
2. 优化动机
通过系统分析,我们发现 Decode 阶段的性能瓶颈主要来自以下两个方面:
2.1 性能瓶颈分析
瓶颈 1: 访存开销过大
- KV Cache 访存:频繁读取 KV Cache 带来的访存开销
- 完整权重加载:纯 DP 策略导致需读取完整模型权重
- 影响:矩阵乘法性能下降,TPOT(Time Per Output Token)增加
瓶颈 2: 显存占用受限
- KV Cache 空间占用:限制了可并发处理的序列数量
- 完整权重存储:纯 DP 导致单卡权重负载过大
- 影响:无法增大 batch size,整体吞吐量受限
2.2 优化思路:”以通信换存储”
设计理念
在现代 Transformer 模型结构中,不同 Linear 层的权重规模存在显著差异,其计算强度也随之不同。在 Decode 阶段,由于输入序列长度固定为 1,计算高度受限于内存带宽(memory-bound)。此时,大规模 Linear 层会带来两方面性能瓶颈:
- 显存压力:完整加载大权重矩阵导致单卡显存占用过高,限制 batch size 或阻碍模型部署
- 访存开销:GEMM(通用矩阵乘法)操作需从 HBM(High Bandwidth Memory)加载大量权重数据,加剧内存带宽竞争,降低单步推理速度,恶化整体 TPOT
优化策略
如图 1 所示,假设 OP2 代表一个典型的大型 Linear 层。若其张量并行策略完全遵循全局统一的纯 DP 配置,则无法有效缓解上述瓶颈。
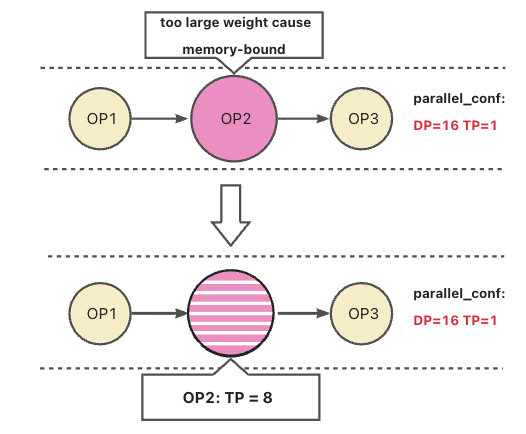
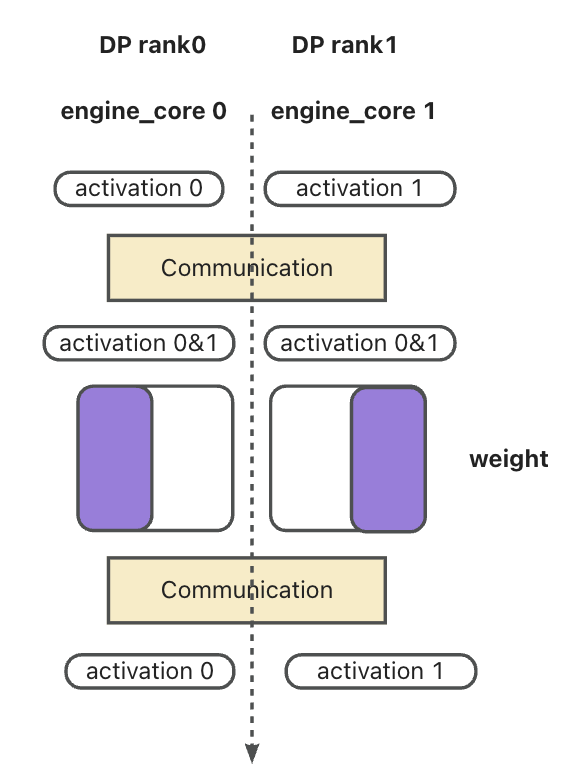
为此,我们提出对 OP2 这类关键大权重模块启用跨 DP 并行组的细粒度张量并行(Fine-Grained Tensor Parallelism)。如图 2 所示,通过在 DP 组之间对 OP2 的权重进行切分与分布式计算,可显著降低:
- 单卡显存占用
- GEMM 访存量
代价是需要在 GEMM 前后引入对跨 DP 的激活值通信,以保证计算精度正确性。
预期收益
- 显存优化:降低需加载的权重大小,提高整体并发能力,增强系统吞吐
- GEMM 性能提升:减少访存量,加速矩阵乘法运算,改善 TPOT 表现
2.3 DeepSeek-R1 模型结构分析
针对 DeepSeek-R1 模型,我们首先分析其模型结构及显存占用分布(参见图 3 和图 4)。
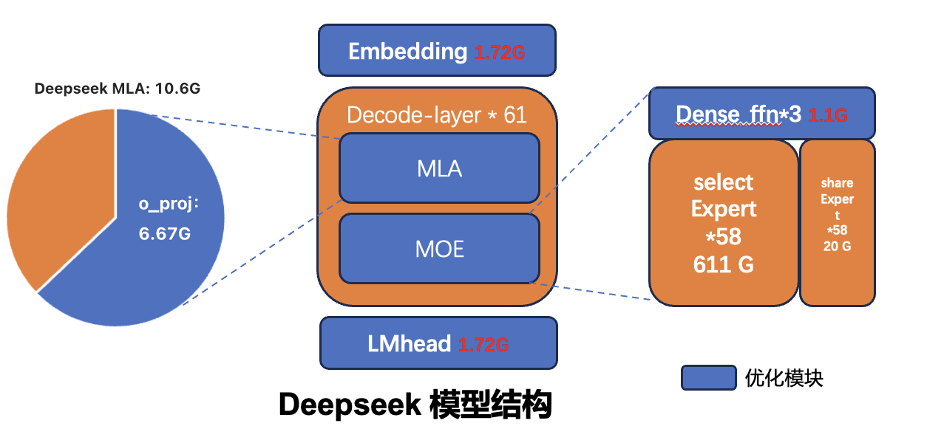
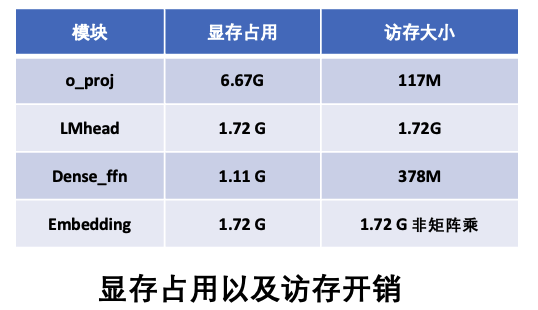
关键模块分析
通过分析,我们识别出以下四个关键模块作为细粒度张量并行的优化对象:
1. O_proj(Attention 输出矩阵)
- 权重规模: 6.67 GB(占 Attention 模块 10.6 GB 显存的 62.9%)
- 分布特征: 分布在 61 层,单层权重约 117 MB
- 访存特征: 实际 GEMM 访存量为 117 MB/层,相对适中
- 优化潜力: 显存优化潜力大,但需权衡通信开销
2. LM Head(语言模型输出头)
- 权重规模: 1.72 GB
- 访存特征: GEMM 访存量为 1.72 GB,带来巨大访存开销
- 优化潜力: 高,访存密集型操作,切分收益明显
3. Embedding(词嵌入层)
- 权重规模: 1.72 GB
- 计算特征: 非 GEMM 运算,采用查表映射(table lookup)
- 访存特征: 引入巨大的访存开销
- 优化潜力: 高,通过切分可显著降低访存压力
4. Dense FFN(前馈神经网络)
- 权重规模: 1.11 GB(仅存在于前三层)
- 访存特征: 单层访存开销为 378 MB,相对较大
- 优化潜力: 中等,访存开销足以覆盖通信成本
面临的技术挑战
在确定优化目标模块后,我们需要解决以下关键问题:
- 通信策略设计
- 不同模块的计算特性各异(升维/降维、单层/双层 MLP、矩阵乘/查表)
- 需要针对性设计通信模式
- 需要建立通信时间的理论模型,以确保最佳通信效率
- 切分粒度确定
- 需要考虑具体集群环境的特性
- 需要评估集群内部的通信效率
- 需要判断是否具备高速通信能力(如 NVLink、IB 等)
- 精度保证
- TP 切分会引入 Reduce 操作
- 需要确保数值精度不会显著下降
- 需要验证最终推理结果的正确性
为了探索不同场景下的切分方式,我开发了一个通用性 demo,可灵活支持各类切分策略与通信模式的组合: https://github.com/zzhx1/CustomTP_Demo
3. 技术方案设计
基于上述分析,我们针对四个关键模块分别设计了细粒度张量并行切分策略。
3.1 O_proj 矩阵切分方案
社区 PR: feat: oproj tensor parallelism in pure DP and graph-mode scenarios
切分策略
采用 All-to-All + 行切分矩阵乘 + Reduce-Scatter 的三阶段策略:
- All-to-All: 在 DP 组间重新分布激活值
- 行切分 GEMM: 各计算卡负责权重矩阵的不同行切片
- Reduce-Scatter: 聚合并分散计算结果
实现流程
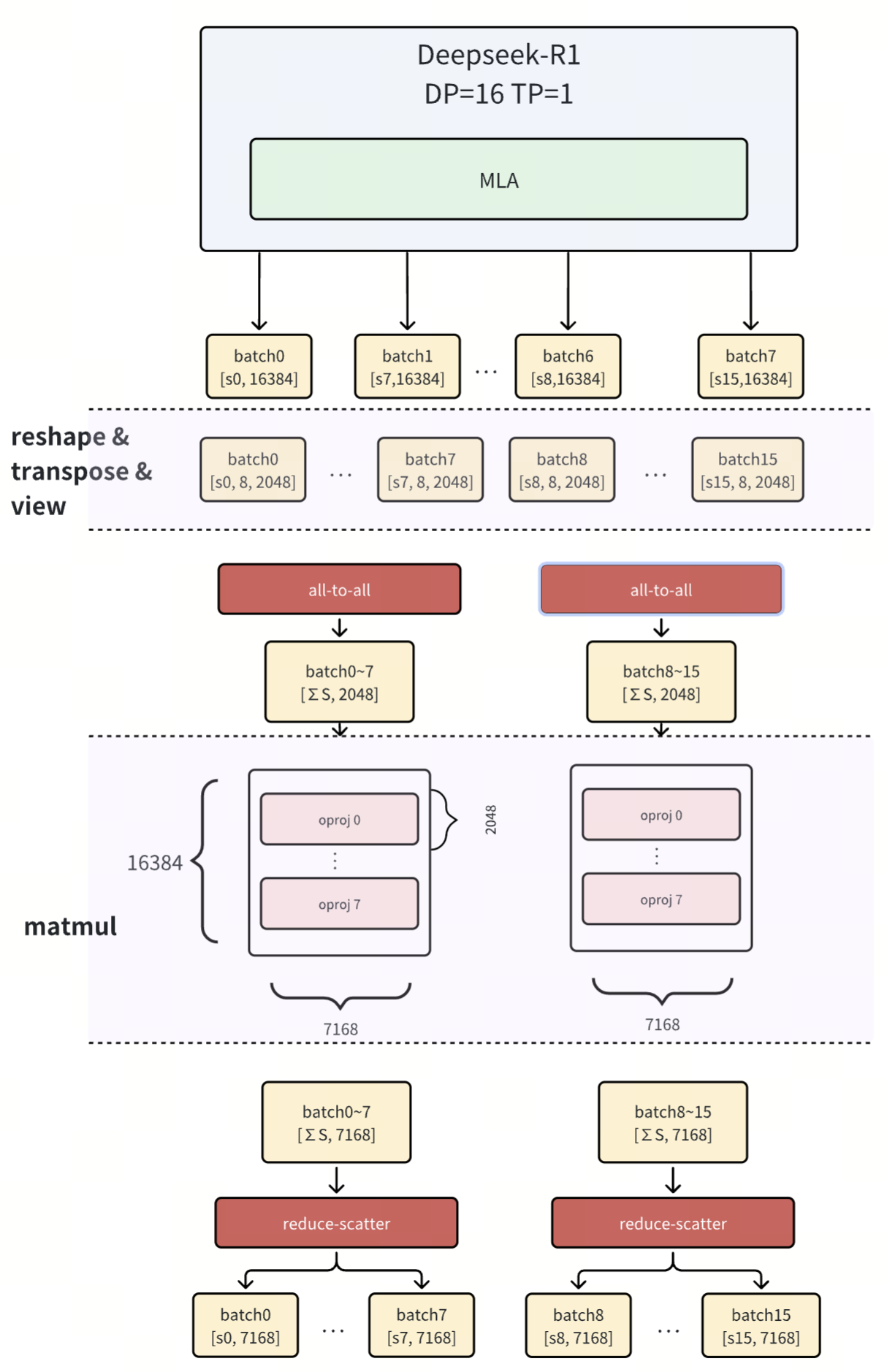
关键设计要点:
- 利用 Attention 输出的高维特征,通过行切分充分利用各计算卡
- All-to-All 确保数据正确分布到对应的计算卡
- Reduce-Scatter 高效完成结果聚合,避免全局通信瓶颈
3.2 LM Head 矩阵切分方案
社区 PR: Feat: Add custom lmhead tensor model parallel
切分策略
采用 All-Gather + 列切分矩阵乘 + All-to-All 的三阶段策略:
- All-Gather: 收集完整的输入激活值
- 列切分 GEMM: 各计算卡负责权重矩阵的不同列切片
- All-to-All: 重新分布输出结果
实现流程
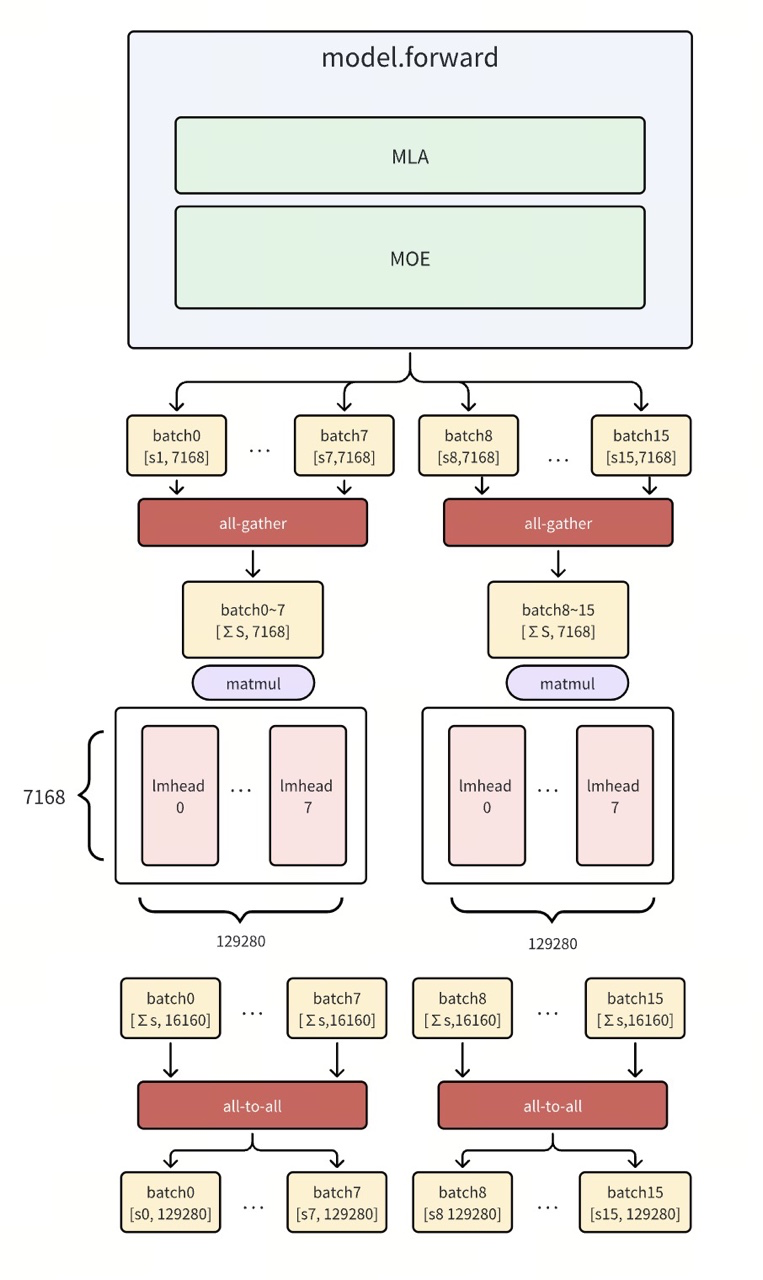
关键设计要点:
- LM Head 执行词表映射,输出维度等于词表大小
- 列切分使得各卡计算不同词汇的 logits
- All-to-All 保证最终输出的正确性
3.3 Embedding 矩阵切分方案
社区 PR: Feat: Add custom Embedding tensor model parallel
切分策略
采用 All-Gather + 列切分查表 + Reduce-Scatter 的三阶段策略:
- All-Gather: 收集完整的 token IDs
- 列切分查表: 各计算卡负责 Embedding 表的不同列切片
- Reduce-Scatter: 聚合并分散 Embedding 向量
实现流程
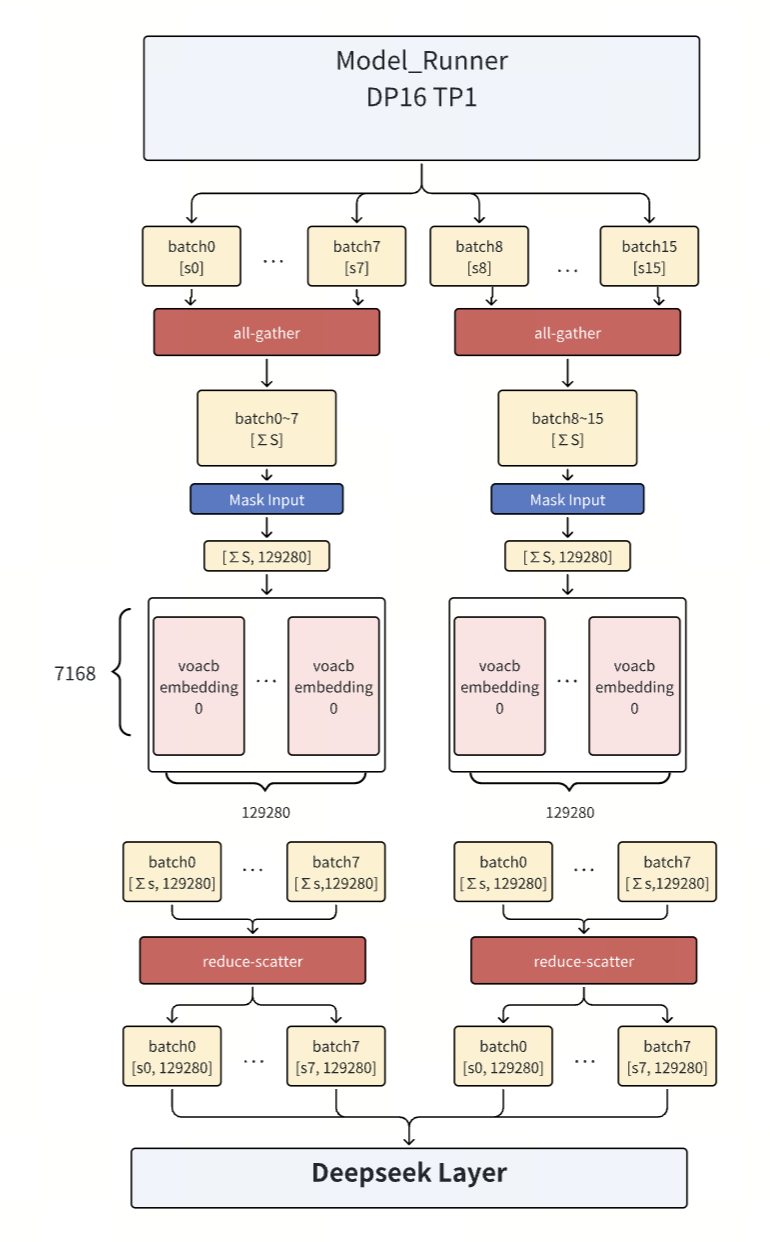
关键设计要点:
- Embedding 操作为查表映射,非标准 GEMM
- 列切分使得各卡存储 Embedding 表的不同特征维度
- Reduce-Scatter 完成特征聚合,输出完整的 Embedding 向量
3.4 Dense FFN(MLP)切分方案
社区 PR: Custom Dense FFN tensor parallelism
切分策略
针对 DeepSeek 前三层的 Dense FFN,采用 All-Gather + 列切分 + 行切分 + Reduce-Scatter 的四阶段策略:
- All-Gather: 收集完整的输入激活值
- 列切分 GEMM(第一层): 升维变换,各卡负责不同隐藏单元
- 行切分 GEMM(第二层): 降维变换,各卡负责不同输入特征
- Reduce-Scatter: 聚合并分散最终输出
实现流程
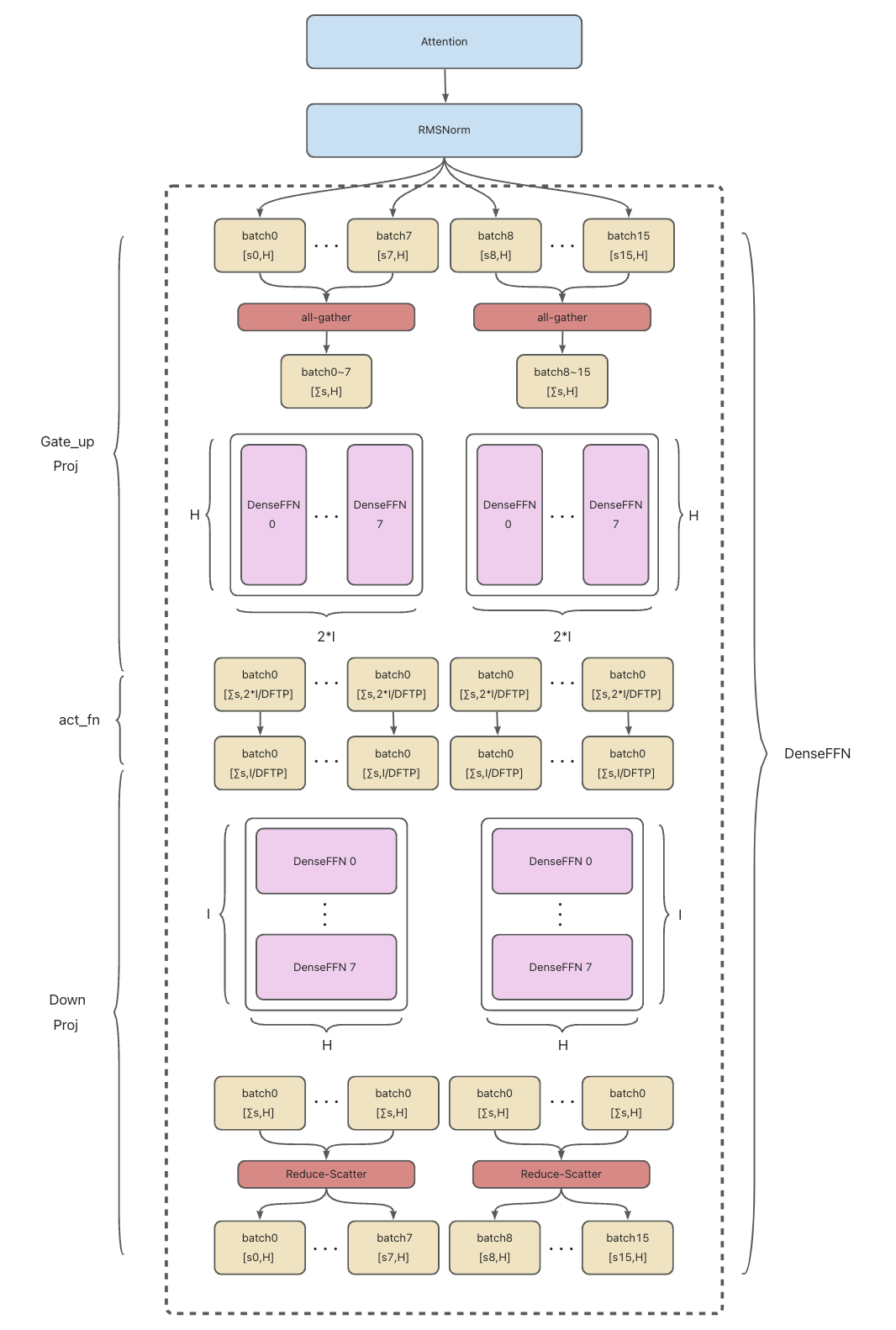
关键设计要点:
- FFN 包含两次矩阵乘法(升维+降维)
- 第一层列切分:各卡计算中间隐藏层的不同部分
- 第二层行切分:利用第一层的切分结果,减少通信
- 仅需在首尾进行通信,中间计算完全并行
4. 实验验证与性能分析
4.1 实验环境
- 硬件平台: 昇腾 A2 和 A3
- 模型: DeepSeek-R1
- 测试节点: Decode 节点
- TP 配置: 细粒度切分规模为 8(TP=8)
4.2 实验结果
各模块性能收益统计
| 模块 | 切分配置 | 显存收益 | TPOT 收益 (batch=24) |
收益分析 |
|---|---|---|---|---|
| O_proj | TP=8 | 5.8 GB | -1.5 ms(劣化) | 显存收益显著,但通信开销导致 TPOT 劣化 |
| LM Head | TP=8 | 1.51 GB | +1.2 ms(优化) | 访存密集型,切分显著提升性能 |
| Embedding | TP=8 | 1.51 GB | +1.0 ms(优化) | 查表访存优化效果明显 |
| Dense FFN | TP=8 | 0.9 GB | +1.0 ms(优化) | 访存优化覆盖通信成本 |
| 总计 | - | 9.72 GB | ~+1 ms(净优化) | 整体显存大幅降低,TPOT 略有提升 |
4.3 关键模块深度分析
O_proj 模块分析
显存收益:
- 单模块收益最大,达到 5.8 GB
- 占 Attention 模块显存的 62.9%
TPOT 劣化原因:
- 单层权重仅 117 MB,访存压力本身不高
- TP 切分引入了两次 AllReduce 通信
- 通信开销(~1.5 ms)无法被访存优化所抵消
适用场景:
- 显存受限场景,需要大幅降低显存占用
- 对 TPOT 要求不极致苛刻的应用
LM Head 模块分析
性能提升关键因素:
- 原始权重为 1.7 GB,访存密集度极高
- 单次推理需读取完整 1.7 GB 权重
- TP 切分显著缓解访存瓶颈
综合收益:
- 显存节省 1.51 GB
- TPOT 优化 1.2 ms
- 性能-显存双重收益
Embedding 模块分析
特殊性:
- 计算方式为查表映射,而非标准 GEMM
- 访存模式与 LM Head 类似,访存压力大
优化效果:
- 显存节省 1.51 GB(与 LM Head 对称)
- TPOT 优化 1.0 ms
- 查表访存优化效果显著
Dense FFN 模块分析
权重特征:
- 单层权重体积相对较小(1.11 GB / 3 层)
- 单层访存开销为 378 MB
优化有效性:
- 访存优化足以覆盖通信成本
- TPOT 优化约 1.0 ms
- 对前三层的推理性能提升明显
4.4 整体评估
显存优化总结
细粒度 TP 切分(TP=8)在整体上显著降低 Decode 节点显存占用:
- 总显存节省: 9.72 GB
- 相对降幅: 显著提升 GPU 利用率
- 应用价值: 可支持更大 batch size,提升系统吞吐量
TPOT 性能总结
整体 TPOT 性能略有提升:
- 净优化: ~1 ms(batch=24)
- 关键贡献者: LM Head(+1.2 ms)、Embedding(+1.0 ms)、Dense FFN(+1.0 ms)
- 主要损耗: O_proj(-1.5 ms)
策略建议
基于实验结果,我们提出以下部署策略建议:
- 显存受限场景(推荐全部启用)
- 所有四个模块均启用细粒度 TP
- 获得最大显存收益(9.72 GB)
- 接受小幅 TPOT 开销(净优化 ~1 ms 或持平)
- TPOT 敏感场景(选择性启用)
- 启用 LM Head + Embedding + Dense FFN
- 关闭 O_proj 切分
- 平衡显存节省(3.92 GB)与 TPOT 优化(+3.2 ms)
- 平衡场景(默认推荐)
- 启用所有模块
- 在实际部署中根据具体负载动态调整
5. 总结与展望
5.1 核心贡献
本工作针对 DeepSeek-R1 模型 Decode 阶段的性能瓶颈,提出了细粒度张量并行优化方案:
- 系统性分析: 识别出 O_proj、LM Head、Embedding、Dense FFN 四个关键瓶颈模块
- 定制化策略: 针对不同模块的计算特性,设计差异化的 TP 切分与通信方案
- 显著收益: 在昇腾 A2/A3 平台上验证,实现 9.72 GB 显存节省和 ~1 ms TPOT 净优化
- 开源贡献: 所有优化方案已合入 vllm-ascend 社区
5.2 适用场景
该优化方案特别适用于以下场景:
- 显存受限的大规模模型部署
- 需要高并发支持的在线推理服务
- PD 分离架构的 Decode 节点优化
5.3 未来工作
- 扩展到更多模型: 验证在其他 Transformer 架构(如Qwen、GLM)上的适用性
- 通信-计算融合: 进一步优化通信与计算的重叠,降低端到端延迟
- 硬件适配: 针对不同硬件平台(GPU、NPU)优化通信原语
- vllm 主社区适配
附录: Q&A
Q1: 为什么 O_proj 切分会导致 TPOT 劣化?
A: O_proj 虽然权重规模大(6.67 GB),但分布在 61 层,单层仅 117 MB。在 Decode 阶段,单层 117 MB 的访存压力相对适中,无法成为显著瓶颈。然而,TP 切分引入了两次通信(前后各一次),通信开销超过了访存优化带来的收益,因此整体 TPOT 劣化。
Q2: 如何确定最优的 TP 切分粒度?
A: 最优 TP 粒度取决于多个因素:
- 集群通信带宽: 高速互联(如 NVLink、IB)支持更大的 TP 粒度
- 模块权重规模: 越大的权重矩阵,越适合更大的 TP
- Batch size: 更大的 batch size 可以摊销通信开销
- 实验验证: 建议通过 profiling 在实际环境中测试不同 TP 粒度的性能
Q3: 增大batch size 是否会进一步的劣化
A: 理论上,batch size的增加,必然带来通信时间的增加,但是deocde 的激活值非常小,短时间无法达到通信密集,可预见的事通信时间会缓慢增加,直到达到通信密集之后,通信时间会显著增加。
Q4: 该方案是否适用于 Prefill 阶段?
A: 不完全适用。Prefill 阶段的特征与 Decode 阶段截然不同: Prefill 是 compute-bound,适合全局大 TP,Decode 是 memory-bound,需要细粒度优化。细粒度 TP 主要针对 Decode 阶段的访存瓶颈,在 Prefill 阶段可能无法带来收益甚至引入额外开销。
Q5: 该方案是否适合混布?
A: 混布是否开启该方案,必须考虑在prefill引入该方案造成的影响,目前不推荐o_porj和mlp切分在混布情况下使用,但是可以开启embedding和lmhead切分,这两个操作不管是prefill或者decode其激活值的大小都非常的小,并且整个模型只有一次计算,因此在混布情况下开启这两个切分是没有问题的。
Q6: 该方案在vllm-ascend中如何使用
A: 详细请查看 https://docs.vllm.ai/projects/ascend/en/latest/user_guide/feature_guide/Fine_grained_TP.