Kubernetes 调度器原理与自定义插件开发实践
一、背景介绍
kube-scheduler 是 Kubernetes 集群的核心组件之一,主要负责集群资源的调度功能。它通过特定的调度算法和策略,将 Pod 分配到最优的工作节点(Node)上,从而实现集群资源的合理利用和充分分配,这也是我们选择使用 Kubernetes 的重要理由之一。
默认情况下,kube-scheduler 提供的原生调度器能够满足绝大多数业务场景,确保 Pod 被分配到资源充足的节点运行。但在实际的生产环境中,业务逻辑往往更加复杂。例如,我们可能需要将某类 Pod 严格限制在特定的节点上运行,或者某些节点只能用于运行特定类型的应用。为了满足这些精细化的需求,我们需要深入理解 Kubernetes 的调度机制,并掌握编写自定义调度插件(Scheduling Plugins)的能力。
二、Kubernetes Pod 部署流程
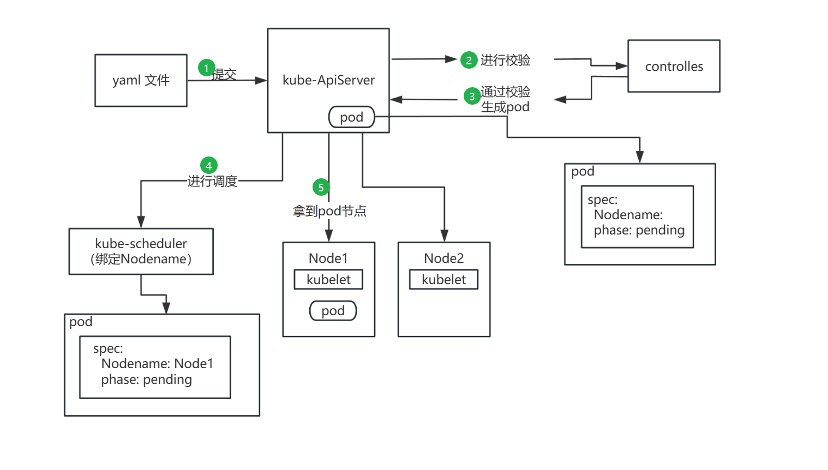
Kubernetes 中 Pod 的总体部署流程如图所示,大致包含以下步骤:
- 提交请求:用户编写好 YAML 配置文件,向
kube-apiserver提交创建请求。 - 准入控制:
kube-apiserver接收到请求后,首先通过 Webhooks 和 Controllers 进行一系列校验(准入控制)。 - 生成 Pod 对象:校验通过后,
kube-apiserver在集群中生成一个 Pod 对象。此时,该 Pod 的nodeName字段为空,状态(Phase)为Pending。 - 调度过程:
kube-scheduler通过 Watch 机制监听到集群中出现了nodeName为空的 Pod,将其标记为“未调度”状态。- 调度器对该 Pod 执行一系列调度算法,包括过滤(Filter)和打分(Score)。
- 选出最合适的节点后,调度器将该节点的名称绑定到 Pod 的
spec.nodeName上,完成调度并更新数据到 API Server。
- 节点执行:
- 目标节点上的
kubelet监听到该 Pod 被分配给自己。 kubelet开始执行容器创建、存储挂载、网络配置等操作。- 所有资源准备就绪后,Pod 状态更新为
Running,至此,一个完整的调度部署过程结束。
- 目标节点上的
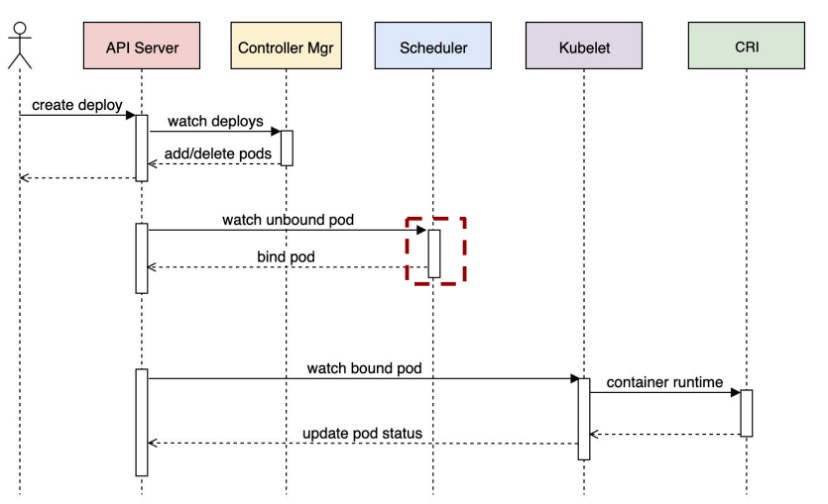
三、调度流程概览
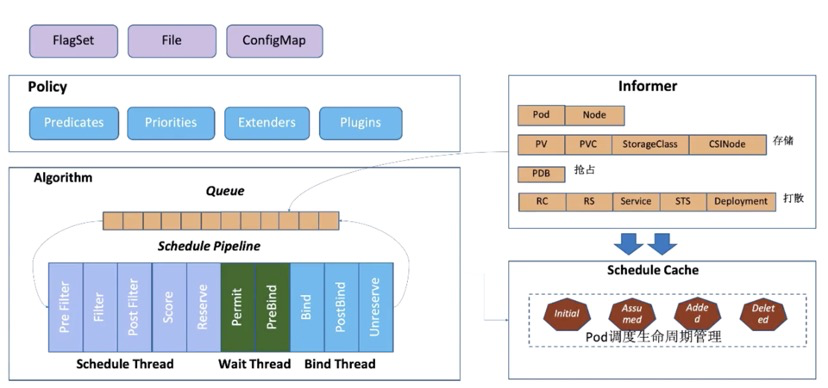
调度器的核心工作流程涉及多个组件的协同,主要包括输入源、策略控制、数据缓存和核心算法流水线。
1. 输入来源与配置
- FlagSet / File:通过命令行参数或配置文件指定调度器参数。
- ConfigMap:存储非敏感的配置数据,用于动态调整。
2. 调度策略 (Policy)
- 过滤器 (Predicates):快速筛选出符合硬性条件的节点。
- 打分器 (Priorities):对筛选后的节点进行优先级打分。
- 扩展调度器 (Extenders):支持外部自定义的 HTTP 回调式调度策略。
- 插件扩展点 (Plugins):当前主流的 Scheduler Framework 扩展机制。
3. 数据缓存 (Informer)
调度器启动时,通过 Kubernetes 的 Informer 机制(List+Watch)从 kube-apiserver 获取 Pods、Nodes、PV、PVC 等数据,并将这些数据预处理后存储在调度器的本地 Cache 中,以提高调度性能。
4. 调度算法流水线 (Algorithm)
调度工作流主要由三个并发线程模型组成:
Scheduler Thread(调度主线程):
核心调度逻辑在此执行,大致流程为:PreFilter->Filter->PostFilter->Score->Reserve。- Filter:筛选符合 Pod Spec 要求的节点。
- Score:对筛选出的节点进行打分排序。
- Reserve:将 Pod 与最优节点的关联信息写入 NodeCache(内存态预占),让后续等待调度的 Pod 能感知到资源已被占用。
Wait Thread(等待线程):
用于处理需等待的关联资源。例如等待 PVC 对应的 PV 创建成功,或在 Gang 调度中等待关联 Pod 组一同就绪。此阶段会进行 Permit(许可)检查。Bind Thread(绑定线程):
负责将 Pod 与 Node 的绑定关系持久化到kube-apiserver。调度完成后,会更新 Scheduler Cache(如 Pod 和 Node 的缓存数据)。
四、调度详细流程
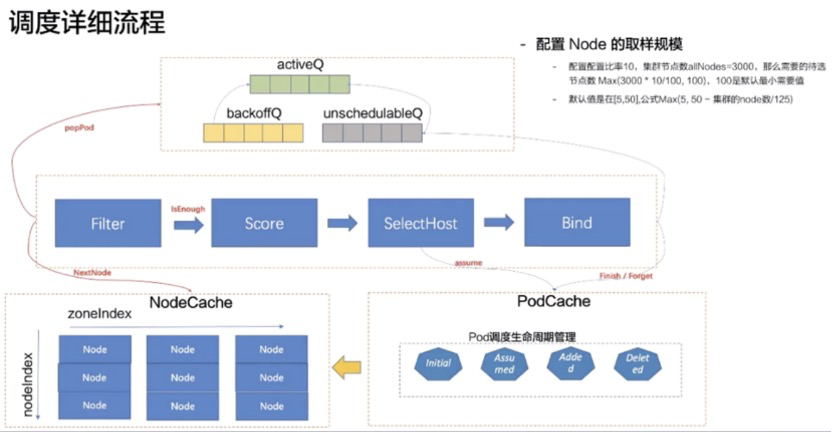
深入剖析 Scheduler Pipeline 的工作原理,我们可以看到更细致的队列管理和数据流转。
1. 调度队列 (SchedulingQueue)
调度队列包含三个子队列:
- activeQ(活跃队列):
调度器启动时,所有待调度的 Pod 首先进入此队列。它是一个优先队列,按照 Pod 优先级进行排序出队。 - backoffQ(退避队列):
当 Pod 因暂时性原因(如资源短缺、调度冲突)调度失败,或调度过程中 Cache 发生变化时,会进入此队列。该队列采用指数退避策略(例如重试间隔依次为 1s, 2s, 4s, …, max 10s),避免在资源不可用时频繁无效重试。 - unschedulableQ(不可调度队列):
当 Pod 因持久性原因(如请求的资源总量超过集群上限)无法调度时进入此队列。通常需等待集群状态发生显著变化(如新节点加入、PV 释放)才会被移出。该队列每 30s 轮询一次,或者如果 Pod 停留超过 60s,也会被尝试重新移回activeQ。
2. 调度流水线执行逻辑
- 采样与过滤:
在 Filter 阶段,如果集群节点规模巨大,调度器通过采样算法(配置比例)选取部分节点进行过滤和打分,而非全量遍历,从而提升效率。 - 容灾与分散:
为保证高可用,NodeCache 中的节点是按 Zone(可用区)分组的。在筛选节点时,调度器维护一个zoneIndex和nodeIndex。- 逻辑:
zoneIndex从左向右轮询,nodeIndex自增。即每次从不同的 Zone 中取一个 Node 进行判断。 - 目的:确保筛选出的候选节点在物理区域上足够分散,避免单点故障。
- 逻辑:
- 预占与绑定:
当 Filter 和 Score 阶段选出最优节点(SelectHost)后,进入 Reserve 阶段。此时修改 Pod 在 PodCache 中的状态为Assumed(内存预占)。随后进入 Bind 阶段,调用 API Server 将nodeName持久化到 etcd。只有当 Informer 监听到持久化成功的数据后,Pod 状态才会转变为Added。
五、K8s 自定义调度插件扩展点
Kubernetes 推出了 Scheduling Framework,将调度过程定义为架构良好的“扩展点”(Extension Points)。用户只需实现特定接口(Interface)并注册到对应的扩展点,即可在不修改核心代码的情况下定制调度逻辑。
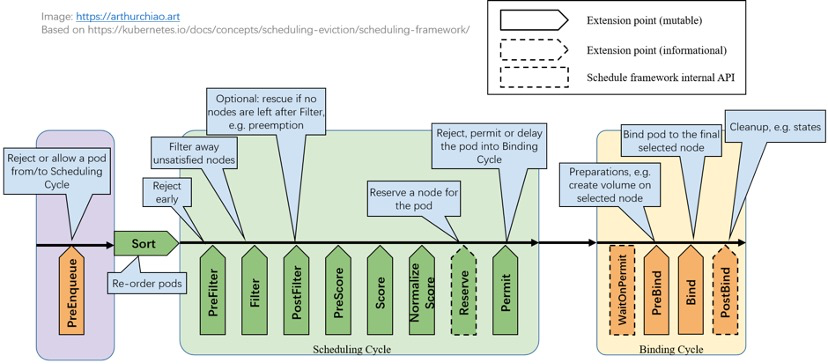
一个完整的调度周期分为 Scheduling Cycle(调度周期,纯内存操作)和 Binding Cycle(绑定周期,涉及外部调用)。主要扩展点如下:
- QueueSort:决定 Pod 在
activeQ中的排序规则(即优先级)。同一时刻只能启用一个 Sort 插件。 - Pre-filter:调度前的预处理,可检查集群或 Pod 的前置条件。若返回 Error,调度终止。
- Filter:核心扩展点。用于过滤不符合要求的节点。任何一个 Filter 插件返回失败,该节点即被排除。
- Post-filter:通知型扩展点。通常用于处理 Filter 失败后的逻辑(如触发抢占 Preemption)。
- Scoring:核心扩展点。对 Filter 后的节点进行打分。
- Normalize scoring:在最终排序前,对分值进行归一化处理或修正。
- Reserve:通知型扩展点。在绑定前锁定资源,防止资源超卖。
- Permit:用于阻止或延迟绑定。支持 Approve(批准)、Deny(拒绝)或 Wait(等待)三种操作(常用于 Gang 调度)。
- Pre-bind:绑定前的执行逻辑,例如挂载网络卷。
- Bind:核心扩展点。执行真正的绑定操作(将 Pod 绑定到 Node)。
- Post-bind:绑定成功后的通知,常用于资源清理。
- Unreserve:若在 Reserve 之后绑定失败,触发此扩展点以释放预占资源。
开发提示:
- 一个插件(Plugin)可以同时实现多个扩展点接口(如既实现 Filter 又实现 Score)。
- 这些插件基于 Go Plugin 机制,通常需要在编译阶段静态链接到调度器二进制文件中。
- 源码接口定义位于:
pkg/scheduler/framework/v1alpha1/interface.go。
六、实践:编写一个简单的 HelloWorld 插件
本示例将开发一个简单的调度插件 helloworld,其逻辑是:强制将 Pod 调度到名称为 k8s-node1 的节点上,否则调度失败。
此示例主要演示插件的注册与部署流程(In-Tree 模式)。
1. 编写插件源码
在 Kubernetes 源码目录 pkg/scheduler/framework/plugins 下创建 helloworld 文件夹,并新建 helloworld.go:
1 | package helloworld |
2. 注册插件
修改 pkg/scheduler/framework/plugins/registry.go 文件,将插件注册到调度器注册表中:
1 | import( |
3. 编译与构建镜像
你需要具备 Kubernetes 源码编译环境。
1 | # 切换到 k8s 源码目录并编译 kube-scheduler |
4. 部署自定义调度器
编写 hello-world-scheduler.yaml,包含 RBAC 设置、ConfigMap 配置及 Deployment 部署。
关键点:在 ConfigMap 中通过 KubeSchedulerConfiguration 启用我们编写的 helloWorld 插件。
1 | apiVersion: v1 |
5. 验证与测试
应用配置:
1 | kubectl create -f hello-world-Scheduler.yaml |
检查运行状态:
1 | kubectl get pod -n kube-system -l component=scheduler |
创建测试 Pod:
创建一个指定使用 hello-world-scheduler 的 Pod。
1 | apiVersion: v1 |
验证结果:
成功调度:查看 Pod 事件,确认是否被调度到
k8s-node1。1
kubectl describe pod pod1
输出示例:
Normal Scheduled … hello-world-scheduler Successfully assigned default/pod1 to k8s-node1
故障测试:
- 将
k8s-node1关机或标记为不可调度。 - 删除并重建
pod1。 - 观察 Pod 状态,应处于
Pending状态,且 Event 提示调度失败(NodeNotReady 或类似原因),证明我们的 Filter 逻辑生效,确实只允许调度到该节点。
- 将
reference:
k8s 官网:
https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/
https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/scheduling-framework/
https://kubernetes.io/zh-cn/docs/reference/scheduling/
out-of-tree plugin 开发方式
https://github.com/kubernetes-sigs/scheduler-plugins/blob/master/doc/install.md#create-a-kubernetes-cluster
https://github.com/kubernetes-sigs/scheduler-plugins
实践博客:
https://arthurchiao.art/blog/k8s-scheduling-plugins-zh/
https://isekiro.com/kubernetes%E7%BB%84%E4%BB%B6%E5%BC%80%E5%8F%91-%E8%87%AA%E5%AE%9A%E4%B9%89%E8%B0%83%E5%BA%A6%E5%99%A8%E4%B8%89/
https://zhuanlan.zhihu.com/p/113620537
http://team.jiunile.com/blog/2020/06/k8s-custom-scheduler.html
https://blog.haohtml.com/archives/34665